


Decentralising the Web3 Stack
The Path Towards Decentralisation

It’s Monday!
First the memes, then an exploration of the Web3 tech stack’s progression towards decentralisation.




Decentralising the Web3 Stack
The Path Towards Decentralisation

In the entire ‘Web3 is decentralised! Web3 is not decentralised!’ debate that we dove into last time around, one thing became abundantly clear: to achieve any semblance of decentralisation, the services that make up the Web3 tech stack must be decentralised and trustless themselves. The element of trustlessness is critical here, i.e., not placing complete trust in any one institution or third party for the network to function correctly. Currently, however, there are many services in the Web3 stack that place undue trust onto centralised servers, APIs, and data storage solutions.
However, it’s still early days. There is a lot of brilliant work that is being done to decentralise Web3 infrastructure. Protocols like Arweave, IPFS, The Graph, Chainlink, and Pocket Network, among others*, are all attempting to solve exactly the problems mentioned by Moxie in his article, while immense progress is being made towards the solutions mentioned by Vitalik, such as data availability sampling. Let’s walk through some of these today. But first, let’s look at what the Web3 stack consists of, and where some of these solutions are attempting to fit in.
*While there isn’t enough space in the world to talk about all of the work being done to decentralise the Web3 stack, some other great projects to keep an eye out for include Ceramic Network, Skynet, API3, and Kyve.
The Web3 Stack
Starting with the basics, a technology stack is the set of technologies an organisation uses to build and run an application. It consists of programming languages, frameworks, a database, front-end tools, back-end tools, and applications connected via APIs. The below picture shows what a modern (let’s call it Web 2.0) tech stack looks like:
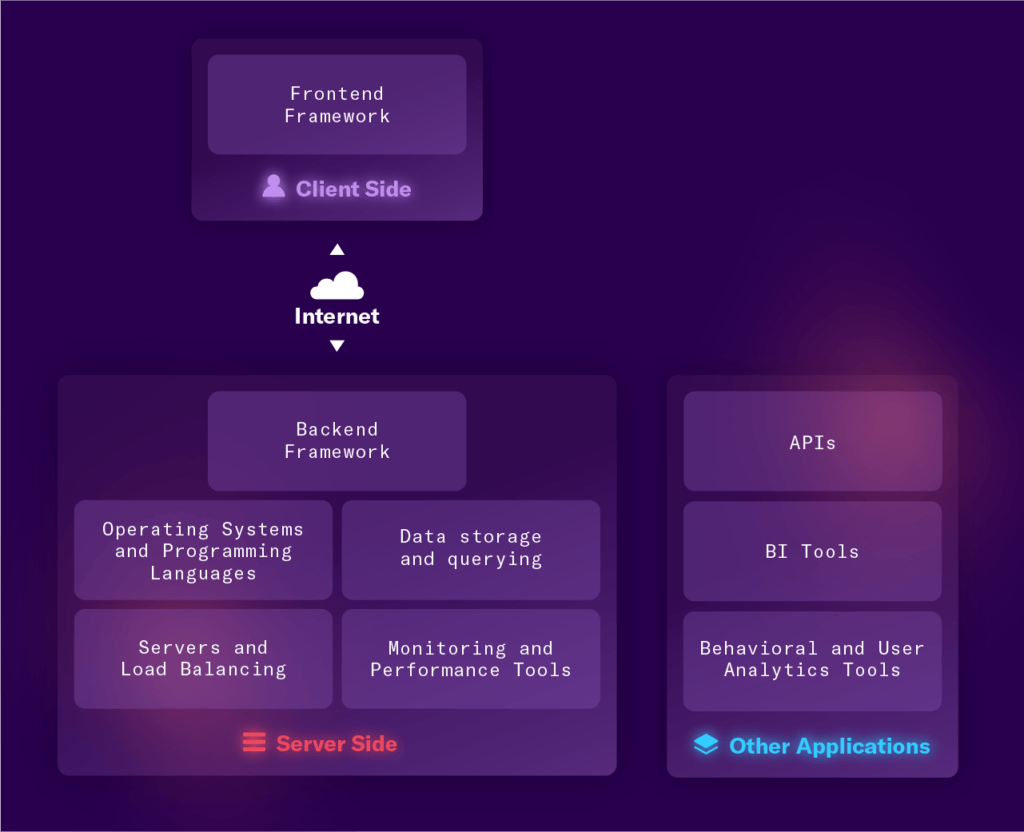
The Web3 stack, on the other hand, is composed a little differently. Below is my representation of how it looks today:
The protocol layer consists of the blockchains on top of which everything else is built. The infrastructure layer is the one which we’re going to focus on today; it sits on top of the protocol layer and contains modular building blocks that perform specific tasks used by the applications built on top of it. This layer consists of all the items an application may need to tap into to build their custom, user-facing applications, such as data storage, data feeds, smart contract audits, identity, etc. The other two layers are the user-centric ones – DeFi applications like Aave and Compound, publishing platforms like Mirror, NFT marketplaces like Rarible, and DEXs like Uniswap are built using the services provided in the infrastructure layer, and users interface with these applications using wallets like MetaMask. For a deeper dive into how a Web3 application is constructed, read Preethi Kasireddy’s fantastic post here.
It is vital for the infrastructure stack itself to be decentralised. Otherwise, the applications built using the infrastructure will not tap into trustless sources of data and will instead rely upon centralised parties whom they will have to trust, in effect replicating the Web 2.0 paradigm. Fortunately, there are several services emerging that are decentralising the Web3 stack and aiming to reduce reliance on centralised servers or parties for data and access.
A Stack of Decentralised Services
Arweave: Data Storage
Arweave, a decentralised data storage protocol, goes some way in addressing Moxie’s findings about data not being stored on-chain. Users pay a single upfront fee, with the protocol matching people who have hard drive space to share with individuals and organisations that need to store data permanently. Arweave is built on top of a ‘blockweave’, a blockchain-like data structure upon which applications, websites, and others are built. Each block in the blockweave is linked to its preceding block and a ‘recall block’, a random second block from the blockweave’s history. Miners provide disk space and replicate the data stored in the network to gain AR tokens, and to mine a new block, they must provide cryptographic proof that they have access to the block’s recall block in Arweave’s Proof of Access (PoA) consensus mechanism. PoA incentivises long-term data storage since miners must access random blocks from the blockweave’s history to mine new blocks and receive mining rewards.
Arweave has a suite of tools and services that allow for applications to be built on top of the blockweave, which projects like Gitopia and Verto have used, and it can also be used to permanently store NFTs. The ecosystem has witnessed rapid growth recently, with an ~86% increase in the number of projects built using Arweave storage from October to December 2021, from 35 to 65. Since the launch of Bundlr in October 2021, which enabled users to pay for Arweave storage with non-Arweave tokens, monthly transactions have increased 16x, data usage has increased 10x from 708GB in August 2021 to 7.8TB in December. Its growth prospects are also on an upward trajectory, with its L1-agnosticism and partnerships with multiple blockchains – it is natively integrated with Polygon, has the SOLAR bridge with Solana, and bridges with L1s like Near, Avalanche, Polkadot, and Cosmos via Kyve Network. Arweave’s growth shows how it is getting easier to interact with the protocol, while also highlighting how early-stage it is – data storage costs still pale in comparison with those offered by AWS, with infinite storage costing $9.5/GB per month on Arweave and $0.015/GB per month on AWS. As the cost of storage decreases over time, the move from centralised services like AWS to decentralised ones like Arweave will become much more of a no-brainer. Now, however, it is more understandable that data is stored off-chain for early-stage projects that desperately need to minimise costs.
IPFS: Content Hosting
The InterPlanetary File System (IPFS) is a P2P, distributed file system that relies on a network of computers that host content. IPFS links point the user towards the content, rather than the location, as most NFTs do today. IPFS splits files up into smaller chunks, distributes them across a network of computers, and assigns each of the chunks an individual hash alongside a unique fingerprint called a content identifier (CID) to allow users to locate them. The location is then served to the user via a P2P connection, similar to how BitTorrent works. The contents on IPFS cannot be changed since the hash itself would change in that case. When a node looks up a file, they query other nodes on who is storing the file, and once they view or download a copy, they cache a copy of the file, in turn becoming another provider of the file until the cache is cleared. IPFS also contains the IPNS decentralised naming system, which maps the CIDs to human-readable domain names when merged with DNSLink.
The Graph: Indexing and Querying Information
One of the foremost solutions to solving the problem of centralised APIs is The Graph, an indexing protocol for querying networks like IPFS or Ethereum. Builders build open APIs called ‘subgraphs’, which are queried with a standard GraphQL API. The Graph network consists of indexers, or the node operators; the consumers, who pay indexers for queries; the curators, who use Graph tokens (GRT) to signal valuable subgraphs to index; and delegators, who stake GRT on behalf of indexers to earn a portion of the indexer rewards. Developers query a P2P network of indexing nodes using GraphQL and verify the results on the client, with any indexer being able to stake GRT to sell their services in the query market and earn rewards for indexing subgraphs and serving queries on those subgraphs. Rather than interacting with centralised servers where data is stored, end users pay to query a decentralised network of indexers via a query engine.
GRT’s tokenomics create a flywheel, where consumers obtain high-quality data from decentralised indexers who compete to provide the best prices; indexers are incentivised to stake GRT and provide high-quality subgraphs to gain consistent rewards over time; and delegators are incentivised to stake GRT and earn a higher percentage of fees from smaller, capital-constrained indexers who they are helping to be more competitive in the market.
The below diagram demonstrates how The Graph works, and why its model is integral to Web3 applications achieving a decentralised, verifiable source of data.

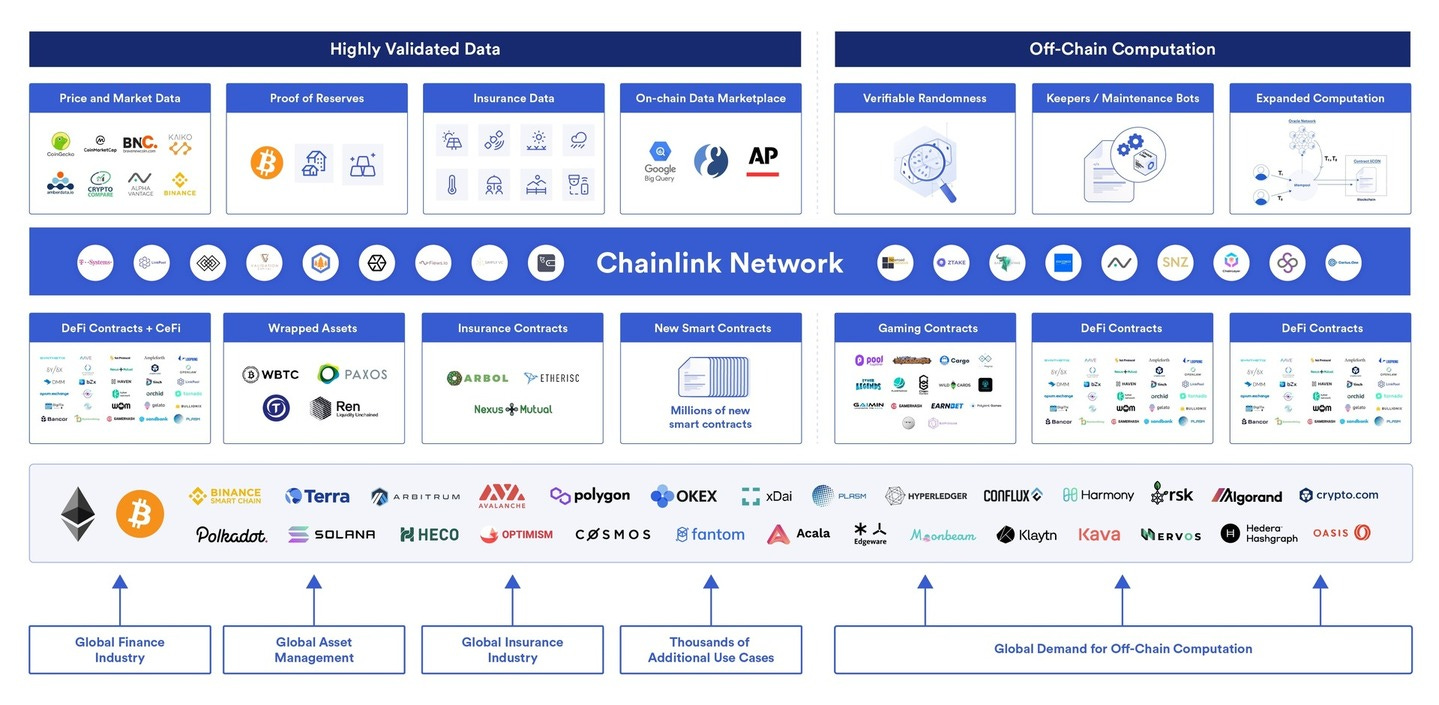
Chainlink: Accessing Verifiable, Real-World Data
Access to real-world data via accurate APIs in a secure, reliable, and decentralised manner is crucial for smart contracts. An oracle translates real-world (off-chain) data to smart contracts (on-chain); however, centralised oracles create a single point of failure in a smart contract. For example, if the data feed that powers a borrowing contract is incorrect and transmits the incorrect price of the collateral submitted by the borrower, it could lead to the borrower getting incorrectly liquidated.
Chainlink attempts to solve this problem. When a smart contract requests off-chain data, Chainlink creates a corresponding smart contract on the blockchain to obtain this data. This smart contract creates 3 sub-contracts: a Reputation Contract (which checks an oracle provider’s track record), an Order-Matching Contract (which delivers the request to the relevant Chainlink nodes, takes their bids on the request, and selects the number and type of nodes to match the request), and an Aggregating Contract (which validates and reconciles the data received from the chosen oracles). Chainlink nodes then translate the request from an on-chain programming language to a language understood by an off-chain API using Chainlink Core software. The API then sends the data back to Chainlink Core, which translates it back and sends it to the Aggregating Contract, which can validate and reconcile data from multiple sources; if, for example, 4 nodes deliver one answer and 1 node delivers another one, Chainlink can discard the one (probably faulty) node.
This method can effectively provide accurate, decentralised data to an essentially endless number of smart contracts across the Web3 ecosystem and is highlighted below in the breadth of Chainlink’s network.
Pocket Network: Verifiably Connecting to Blockchains
A Remote Procedure Call (RPC) is a type of API that allows for developers to run code that can be remotely executed on servers. Developers connect their applications to the blockchain via RPC nodes, which allow them to read blockchain data and send transactions to different networks. For example, when MetaMask is used to make a transaction, the user’s transaction request is routed through an RPC to connect with a node that holds the blockchain data. Currently, due to the increasing cost of maintaining RPC nodes, data flows through centralised RPC nodes that must be trusted to provide the correct information.
Pocket Network uses tokenomics to incentivise a network of RPC nodes to relay data to any blockchain in a decentralised manner. An application submits a relay (API request) which is routed to a public database node, the node services the relay, and sends the response back to the application. When the application submits the relay, an algorithm pseudo-randomly assigns 5 nodes to the application, who handle API requests until they are shuffled to another application later. The nodes are rewarded with POKT tokens in proportion with the number of requests they service, and they stake a certain number of POKT tokens to ensure honest data. Applications, on the other hand, have to stake POKT tokens to begin submitting relay requests. Nodes that are consistently down or return invalid data have their stake slashed. The nodes are thus incentivised to provide good service, or risk being penalised. Pocket ensures decentralisation by periodically replacing nodes and providing backups in case a node goes down.
Pocket is a critical piece of the decentralised Web3 stack since it eliminates the need for applications to pass through centralised intermediaries to communicate with the blockchain. Moreover, a decentralised network of nodes provides several benefits over a centralised system, with the geographical dispersion of the nodes helping minimise latency, and good service theoretically being ensured by the token incentive design.
Other Solutions to Achieve Decentralisation
In addition to the solutions mentioned above, there are several other ways in which Web3 can continue progressing towards greater decentralisation. One of these is data availability sampling.
Currently, to verify transaction validity, blockchains face the dilemma of scalability versus decentralisation. To increase transactions per second (TPS) processed, the hardware requirements of running a full node need to increase – but if the requirements increase, there would be fewer full nodes and the level of centralisation of the network would increase. In order for their work to be verified, validators need to make the transaction data from the blocks they produce readily available; how quickly the data is made available determines the TPS processed by the blockchain. Rather than using full nodes, Ethereum Layer 2 solutions use powerful computers called ‘sequencers’ for transaction computation and execution. Sequencers process transactions off-chain before sending them on-chain to be finalized. Optimistic Rollups like Optimism use ‘fraud proofs’ to keep sequencers honest, which show that a sequencer has included a fraud transaction. Zero-Knowledge (ZK) Rollups like zk-sync, on the other hand, utilise validity proofs (a ZK-SNARK/STARK) which guarantee that none of the transactions were malicious. For both of these, obtaining the sequencer’s transaction data in a timely manner is critical for scalability and trust, and without these, there would be no way of keeping the sequencers honest. Moreover, when the sequencer ‘dumps’ its data onto the data availability layer of the parent blockchain (like Ethereum), the full nodes on Ethereum need to keep up with the sequencer to ensure that it does not withhold any data and save us from having to trust that the sequencer is behaving honestly.
Data availability sampling is a scalable solution to this dilemma. To do this, the data ‘dumped’ by the sequencer should be erasure-coded, i.e., the original data is doubled in size and encoded with redundant data. This allows us to recover the original data with any random 50% of the erasure-coded data and would mean that a malicious sequencer would have to withhold more than 50% of the block’s data. If a full node randomly downloads a piece of data from the block, it would have a <50% chance of getting fooled, and if it repeats this process 7 times, the chance of getting fooled would be <1%. A full node would therefore need to download only a small portion of the data made available by the sequencer on the parent blockchain, allowing this to be done on mobile phones as well, increasing the decentralisation of the network and adding increased trust to rollups.
Closing Thoughts
In the story of Moses, God unshackled his people (the Israelites) from bondage and were to take possession of their Promised Land that ‘flowed with milk and honey’. However, they became convinced that they could not defeat the current inhabitants of that land even though God told them they could and refused to enter. For this lack of belief, he cursed them to wander the wilderness for 40 years, waiting to be led to the Promised Land.
While the journey towards Web3 isn’t quite like that to the Promised Land, the analogy does hold some important parallels. At the first time of asking, the Israelites were not mature enough to displace the incumbents in the Promised Land. They had to face 40 years of growth, development, and maturity to reach a point of readiness. This highlights an important point to keep in mind: reaching an ‘ideal state’ is not immediate. Web3 is still not ready to completely displace its Web 2.0 counterparts. As time goes on, though, there are services and capabilities being developed that are enabling it to become more mature and ready enough to reach the abstract destination of the ‘Promised Land’, which, as in the Biblical analogy, is more of an idealised vision than a concrete, well-defined reality. It is up to the builders of applications being created on top of the Web3 stack to best decide what ‘final’ form this vision of the ‘Promised Land’ will take.
The best articles I’ve read over the last couple of weeks:
To join this journey into the worlds of tech, business, and Web3, subscribe below!
Disclaimer
This is a personal blog. Any views or opinions represented in this blog are personal and belong solely to the article authors and do not represent those of people, institutions or organizations that those authors may or may not be associated with in professional or personal capacity, unless explicitly stated. All content provided on this blog is for informational purposes only. The owner of this blog makes no representations as to the accuracy or completeness of any information on this site or found by following any link on this site. The owner will not be liable for any errors or omissions in this information nor for the availability of this information. The owner will not be liable for any losses, injuries, or damages from the display or use of this information. Any views or opinions are not intended to malign any religion, ethnic group, club, organization, company, or individual.
👇🏽 please hit the ♥️ button below if you enjoyed this post.